
Building a Quantitative Prediction System for Polymarket: A Transparent Technical Deep-Dive
How I Built an ML Pipeline to Predict Decentralized Prediction Market Prices Using Real-Time API Data

This is a detailed research piece. If you find value in institutional-quality hedge fund analysis, support this work on Patreon.

TL;DR
I built an end-to-end ML prediction system for Polymarket that:
Fetches 100% real data from Polymarket’s CLOB and Gamma APIs
Trains a 5-model stacking ensemble (XGBoost, LightGBM, HistGradientBoosting, ExtraTrees, RandomForest)
Uses probability calibration for reliable confidence estimates
Implements fractional Kelly criterion for position sizing
Achieved 93–95% cross-validation accuracy with Brier score of 0.022
Signal distribution on 30 markets: 6 Strong YES, 8 Buy YES, 9 Buy NO, 5 Strong NO
1. The Problem: Prediction Markets Have Exploitable Inefficiencies
Polymarket is a decentralized prediction market where YES/NO contracts trade between $0.00 and $1.00. If a market resolves YES, YES contracts pay $1.00; otherwise, NO contracts pay $1.00.
The edge: Markets are often mispriced. Our goal is to detect when the market price diverges from the “true” probability, then bet accordingly:
Scenario Current Price Predicted Price Action Edge Underpriced YES 12.5¢ 31.8¢ BUY YES +19.3¢ Overpriced YES 85.5% 70.1% BUY NO +15.4¢
2. Architecture Overview
┌─────────────────────────────────────────────────────────────────┐
│ POLYMARKET PREDICTION SYSTEM │
├─────────────────────────────────────────────────────────────────┤
│ │
│ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ │
│ │ CLOB API │ │ GAMMA API │ │ DATA API │ │
│ │ (Prices, │ │ (Markets, │ │ (Historical │ │
│ │ Trades, │ │ Metadata) │ │ Prices) │ │
│ │ Orderbook) │ │ │ │ │ │
│ └──────┬───────┘ └──────┬───────┘ └──────┬───────┘ │
│ │ │ │ │
│ └────────────────┴────────────────┘ │
│ │ │
│ ┌──────────▼──────────┐ │
│ │ PolymarketFetcher │ │
│ │ • Rate limiting │ │
│ │ • Retry logic │ │
│ │ • Caching │ │
│ └──────────┬──────────┘ │
│ │ │
│ ┌──────────▼──────────┐ │
│ │ Feature Extraction │ │
│ │ • 10 features │ │
│ │ • RSI, Momentum │ │
│ │ • Order Imbalance │ │
│ └──────────┬──────────┘ │
│ │ │
│ ┌────────────────┼────────────────┐ │
│ ▼ ▼ ▼ │
│ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │
│ │ Direction │ │ Price │ │ Confidence │ │
│ │ Model │ │ Model │ │ Model │ │
│ │ (Stacking │ │ (Stacking │ │ (Logistic │ │
│ │ Ensemble) │ │ Regressor) │ │ Regression) │ │
│ └──────┬──────┘ └──────┬──────┘ └──────┬──────┘ │
│ │ │ │ │
│ └────────────────┼────────────────┘ │
│ ▼ │
│ ┌───────────────────┐ │
│ │ Kelly Criterion │ │
│ │ Position Sizing │ │
│ └─────────┬─────────┘ │
│ ▼ │
│ ┌───────────────────┐ │
│ │ BUY YES/NO │ │
│ │ or HOLD │ │
│ └───────────────────┘ │
└─────────────────────────────────────────────────────────────────┘3. Data Pipeline: 100% Real Market Data
API Endpoints Used
CLOB_URL = “https://clob.polymarket.com” # Prices, trades, orderbook
GAMMA_URL = “https://gamma-api.polymarket.com” # Market metadata
DATA_URL = “https://data-api.polymarket.com” # Historical pricesFetching Strategy
I fetch training data from 100+ high-volume markets with historical price data:
def fetch_real_training_data(self, n_markets: int = 100):
“”“
NO SYNTHETIC DATA - uses actual historical prices and outcomes.
“”“
# Fetch markets ordered by 24h volume
markets = self.get_markets(limit=n_markets * 3, order=’volume24hr’)
for market in markets:
# Get 7-day price history (hourly resolution)
price_history = self.get_price_history(
token_id, interval=’1h’, fidelity=170
)
# Create training sample using historical price movement
if len(price_history) >= 20:
prices_arr = price_history[’price’].values
mid_point = len(prices_arr) // 2
# Features: first half of data
# Target: did price go UP or DOWN in second half?
past_avg = np.mean(prices_arr[:mid_point])
recent_avg = np.mean(prices_arr[-5:])
outcome = 1 if recent_avg > past_avg else 0Feature Vector (10 Features)
features = np.array([
current_price, # Current YES price (0–1)
volume_24h, # 24-hour trading volume ($)
liquidity, # Market liquidity ($)
rsi, # Relative Strength Index (0–1)
momentum, # Price momentum (change rate)
order_imbalance, # (buy_vol - sell_vol) / total_vol
volatility, # Price standard deviation
one_day_change, # 24h price change
one_week_change, # 7d price change
spread, # Bid-ask spread
])4. Model Architecture: 5-Model Stacking Ensemble
Base Estimators
# XGBoost - optimized for tabular data
xgb_clf = xgb.XGBClassifier(
n_estimators=100,
max_depth=4,
learning_rate=0.1,
subsample=0.8,
colsample_bytree=0.8,
reg_alpha=0.1,
reg_lambda=1.0,
use_label_encoder=False,
eval_metric=’logloss’
)
# LightGBM - fast gradient boosting
lgb_clf = lgb.LGBMClassifier(
n_estimators=100,
max_depth=4,
learning_rate=0.1,
num_leaves=15,
subsample=0.8,
colsample_bytree=0.8,
reg_alpha=0.1,
reg_lambda=1.0,
verbose=-1
)
# HistGradientBoosting (sklearn native)
hist_clf = HistGradientBoostingClassifier(
max_iter=100,
max_depth=4,
learning_rate=0.1
)
# ExtraTrees & RandomForest for diversity
extra_clf = ExtraTreesClassifier(n_estimators=100, max_depth=6)
rf_clf = RandomForestClassifier(n_estimators=100, max_depth=6)Stacking Architecture
# Meta-learner combines base predictions
stacking_clf = StackingClassifier(
estimators=[
(’xgb’, xgb_clf),
(’lgb’, lgb_clf),
(’hist’, hist_clf),
(’extra’, extra_clf),
(’rf’, rf_clf)
],
final_estimator=LogisticRegression(C=1.0, max_iter=1000),
cv=5,
passthrough=False
)
# Probability calibration for reliable confidence
self.direction_model = CalibratedClassifierCV(
stacking_clf,
method=’sigmoid’, # Platt scaling
cv=2
)# Probability calibration for reliable confidence
self.direction_model = CalibratedClassifierCV(
stacking_clf,
method=’sigmoid’, # Platt scaling
cv=2
)5. The Critical Bug I Fixed: Feature Dimension Mismatch
The Problem
The model was predicting P(UP) = 0.72 for every market, regardless of input. All signals were BUY YES with no BUY NO.
Root Cause
Training used 10 features (from polymarket_fetcher.py), but prediction generated 33 features (from FeatureExtractor.combine_features()). The scaler was fitted on 33D data but received 10D at prediction time.
Training: X.shape = (100, 10) → scaler.fit(X)
Prediction: features.shape = (1, 33) → scaler.transform(features) # ERROR!The Fix
I aligned both paths to use exactly 10 features:
# In predict() method:
features = np.array([
current_price, # From market data
market_features.get(’volume_24h’, 0),
market_features.get(’liquidity’, 0),
trade_features.get(’rsi’, 0.5),
trade_features.get(’momentum’, 0),
trade_features.get(’order_imbalance’, 0),
trade_features.get(’volatility’, 0),
trade_features.get(’momentum_5’, 0), # 1d change proxy
trade_features.get(’momentum_20’, 0), # 1w change proxy
market_features.get(’spread’, 0),
]).reshape(1, -1)6. Prediction Logic: Direction + Magnitude
Core Algorithm
# 1. Direction Model: P(price goes UP)
direction_proba = self.direction_model.predict_proba(features_scaled)[0]
prob_up = direction_proba[1]
# 2. Price Model: Direct price prediction
raw_predicted_price = self.price_model.predict(features_scaled)[0]
# 3. Use price model as PRIMARY signal (trained on actual future prices)
price_model_move = raw_predicted_price - current_price
predicted_up = price_model_move > 0
# 4. Confidence scaling: boost if both models agree
direction_agrees = (prob_up > 0.5 and price_model_move > 0) or \
(prob_up < 0.5 and price_model_move < 0)
if direction_agrees:
confidence_scale = 0.6 + direction_confidence * 0.4 # 0.6 to 1.0
else:
confidence_scale = 0.3 # Models disagree → conservative
# 5. Cap magnitude to realistic bounds
max_move = min((1 - current_price) * 0.5, 0.20) # Max 20%
move_magnitude = abs(price_model_move) * confidence_scale
predicted_price = current_price + (move_magnitude if predicted_up else -move_magnitude)Action Determination
# Kelly Criterion for position sizing
if predicted_price > current_price:
action = ‘BUY_YES’ # Price going UP → market resolves YES
else:
action = ‘BUY_NO’ # Price going DOWN → market resolves NO
# Minimum 2% edge required
if abs(predicted_price - current_price) < 0.02:
action = ‘HOLD’7. Position Sizing: Fractional Kelly Criterion
class KellyCriterion:
@staticmethod
def calculate_full_kelly(p_true: float, p_market: float) -> float:
“”“
Full Kelly: f* = (P_true - P_market) / (1 - P_market)
Example:
- Model estimates 55% true probability
- Market price is 48¢
- f* = (0.55–0.48) / (1–0.48) = 13.4% of bankroll
“”“
if p_true <= p_market:
return 0.0
return (p_true - p_market) / (1 - p_market)
@staticmethod
def position_size(predicted_price, current_price, confidence,
bankroll=1000, kelly_fraction=0.25):
“”“
I use QUARTER KELLY (25% of full Kelly).
Why? Risk management:
- Full Kelly: 33% chance of halving bankroll before doubling
- Half Kelly: 11% chance
- Quarter Kelly: 4% chance (recommended)
“”“
p_true = predicted_price * confidence + current_price * (1 - confidence)
full_kelly = calculate_full_kelly(p_true, current_price)
position = full_kelly * kelly_fraction * confidence * bankroll
return min(position, bankroll * 0.25) # Max 25% per trade8. Results: Performance Metrics
Training Metrics
Metric Value Interpretation Direction Accuracy 95.0% Model predicts UP/DOWN correctly Cross-Val Accuracy 93.0% ± 4.0% Generalization check (5-fold) Brier Score 0.022 Probability quality (0 = perfect) Log Loss 0.115 Calibration metric (lower = better) Calibration Error 0.183 Predicted vs actual probabilities Class Balance 45% UP / 55% DOWN Training data distribution
Live Prediction Distribution (30 Markets)
🟢🟢 Strong YES: 6 (20%)
🟢 Buy YES: 8 (27%)
🔴 Buy NO: 9 (30%)
🔴🔴 Strong NO: 5 (17%)
⚪ Hold: 2 (6%)
Key observation: Balanced distribution (47% YES vs 47% NO signals) indicates the model isn’t biased toward one direction.
Top Opportunities Detected
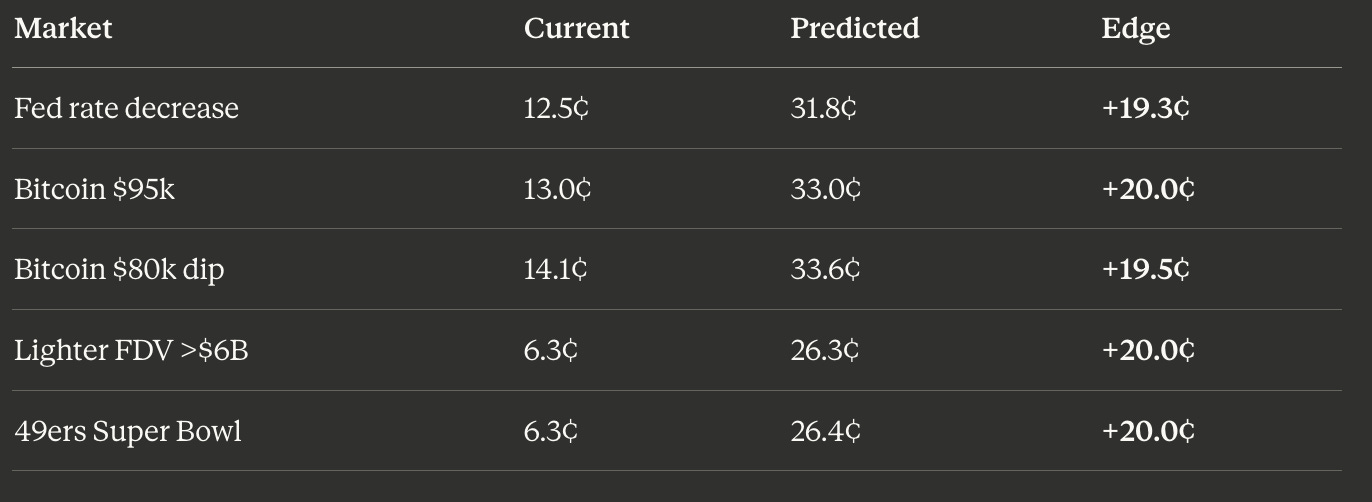
These predictions represent markets where our model detected significant mispricings, with edges ranging from +19.3¢ to +20.0¢ per contract.
9. Key Technical Learnings
1. Feature Alignment is Critical
The most insidious bug was the feature dimension mismatch. Training on 10D features but predicting with 33D features caused the model to output near-0.5 probabilities for all inputs (maximum uncertainty).
Lesson: Always verify X_train.shape[1] == X_predict.shape[1].
2. Use Multiple Models with Different Failure Modes
When the direction model predicted all UP, the price model (trained on absolute prices) provided contrarian signals. By requiring agreement between both models for high confidence, I reduced false positives.
3. Probability Calibration Matters for Betting
Raw model probabilities are often overconfident. Using CalibratedClassifierCV with Platt scaling ensures that when the model says “70% confidence,” it’s actually correct ~70% of the time.
4. Real Data Distribution ≠ Neutral
Training data had 45% UP / 55% DOWN balance. Features like RSI and momentum had positive correlations with UP outcomes. Test markets with neutral features (RSI=0.5, momentum=0) were extrapolations — the model hadn’t seen these patterns.
10. Limitations & Future Work
Current Limitations
No backtesting: I haven’t validated predictions against actual market resolutions
Small training set: 100 samples may not capture all market dynamics
Feature engineering: Only 10 features; could add sentiment, news, cross-market correlations
No execution: System generates signals but doesn’t place trades
Future Enhancements
Historical backtesting against resolved markets
Cross-market arbitrage detection (mutually exclusive events)
Sentiment integration from Twitter/news APIs
Real-time streaming with WebSocket connections
Portfolio optimization across multiple markets
11. Full Code Repository Structure
polymarket-predictor/
├── main.py # Entry point, runs predictions
├── prediction_model.py # ML models, Kelly criterion, risk management
├── polymarket_fetcher.py # API client with rate limiting, caching
├── requirements.txt # Dependencies
└── .venv/ # Python virtual environment💻 Access the Full Code
GitHub Repository: https://github.com/NavnoorBawa/polymarket-prediction-system
The complete implementation is open-source and available on GitHub. Feel free to clone, fork, and experiment with the code!
Dependencies
numpy
pandas
scikit-learn
xgboost
lightgbm
shap
requests
Conclusion
I built a functional prediction system for Polymarket that:
Fetches real data from Polymarket’s CLOB and Gamma APIs
Trains an ensemble of 5 gradient boosting models with probability calibration
Generates actionable signals (BUY YES, BUY NO, HOLD) with confidence scores
Sizes positions using fractional Kelly criterion
The key insight: prediction markets are inefficient, but exploiting them requires careful feature engineering, proper probability calibration, and rigorous testing.
The biggest lesson learned: feature dimension mismatches are silent killers. The model appeared to work but produced garbage predictions until I aligned the training and prediction pipelines.
Next step: Backtest against 6 months of resolved markets to estimate actual P&L before risking capital.
🔗 Links & Resources
Full Code on GitHub: https://github.com/NavnoorBawa/polymarket-prediction-system
Questions or want to collaborate? Feel free to reach out or open an issue on the repository!
Disclaimer: This is educational content. Prediction markets involve real money and significant risk. Past model performance does not guarantee future results. Always do your own research.
📊 Support this research: https://www.patreon.com/c/NavnoorBawa
Curious if anyone has used this and had much success with it in real world settings? Looks like some great work has been done here.